GROUP BY
GROUP BY 절은 데이터들을 원하는 그룹으로 나눌 수 있다.
GROUP BY는 데이터를 그룹별로 나눠 합계, 평균등의 연산을 할 경우 사용된다.
SELECT 문에 지정된 SUM, AVG, COUNT, MAX, MIN 등의 연산 함수들에 따라
합계, 평균, 레코드수, 최대값, 최소값 등을 구하게 된다.
✔️ WHERE는 그룹화 하기 전이고, HAVING은 그룹화 후에 조건
💊 집계 함수와 상수가 함께 SELECT 절에 사용
-- 부서별 사원수 조회
SELECT '2005년' year, deptno 부서번호, COUNT(*) 사원수
FROM emp
GROUP BY deptno
ORDER BY COUNT(*) DESC;
YEAR 부서번호 사원수
------ ---------- ----------
2005년 30 6
2005년 20 5
2005년 10 3
💊 부서별로 그룹하여 부서번호, 인원수, 급여의 평균, 급여의 합을 조회하는 예제
SELECT deptno, COUNT(*), ROUND(AVG(sal)) "급여평균",
ROUND(SUM(sal)) "급여합계"
FROM emp
GROUP BY deptno;
DEPTNO COUNT(*) 급여평균 급여합계
-------- ---------- ---------- ----------
30 6 1567 9400
20 5 2175 10875
10 3 2917 8750
💊 업무별로 그룹하여 업무, 인원수, 평균 급여액, 최고 급여액, 최저 급여액 및 합계를 조회하는 예제
SELECT job, COUNT(empno) "인원수", AVG(sal) "평균급여액",
MAX(sal) "최고급여액", MIN(sal) "최저급여액",
SUM(sal) "급여합계"
FROM emp
GROUP BY job;
JOB 인원수 평균급여액 최고급여액 최저급여액 급여합계
----------- -------- ---------- ---------- ---------- ----------
CLERK 4 1037.5 1300 800 4150
SALESMAN 4 1400 1600 1250 5600
PRESIDENT 1 5000 5000 5000 5000
MANAGER 3 2758.33333 2975 2450 8275
ANALYST 2 3000 3000 3000 6000
💊 GROUP BY 절은 집계 함수 없이도 사용 될 수 있다.(DISTINCT와 용도가 비슷해 짐)
아래 예제는 GROUP BY는 말 그대로 그룹을 나누는 역할을 한다.
-- GROUP BY를 이용한 부서번호 조회 예
SELECT deptno
FROM emp
GROUP BY deptno;
DEPTNO
------
30
20
10SELECT CategoryID FROM Products
GROUP BY CategoryID;
SELECT
Country, City,
CONCAT_WS(', ', City, Country)
FROM Customers
GROUP BY Country, City;
SELECT
COUNT(*), OrderDate
FROM Orders
GROUP BY OrderDate;
SELECT
ProductID,
SUM(Quantity) AS QuantitySum
FROM OrderDetails
GROUP BY ProductID
ORDER BY QuantitySum DESC;
SELECT
CategoryID,
MAX(Price) AS MaxPrice,
MIN(Price) AS MinPrice,
TRUNCATE((MAX(Price) + MIN(Price)) / 2, 2) AS MedianPrice,
TRUNCATE(AVG(Price), 2) AS AveragePrice
FROM Products
GROUP BY CategoryID;
DISTINCT
중복 값 제거
GROUP BY 와 달리 집계함수가 사용되지 않습니다.
GROUP BY 와 달리 정렬하지 않으므로 더 빠릅니다.
SELECT DISTINCT CategoryID
FROM Products;
-- 위의 GROUP BY를 사용한 쿼리와 결과 비교
SELECT COUNT DISTINCT CategoryID
FROM Products;
-- 오류 발생
SELECT DISTINCT Country
FROM Customers
ORDER BY Country;
SELECT DISTINCT Country, City
FROM Customers
ORDER BY Country, City;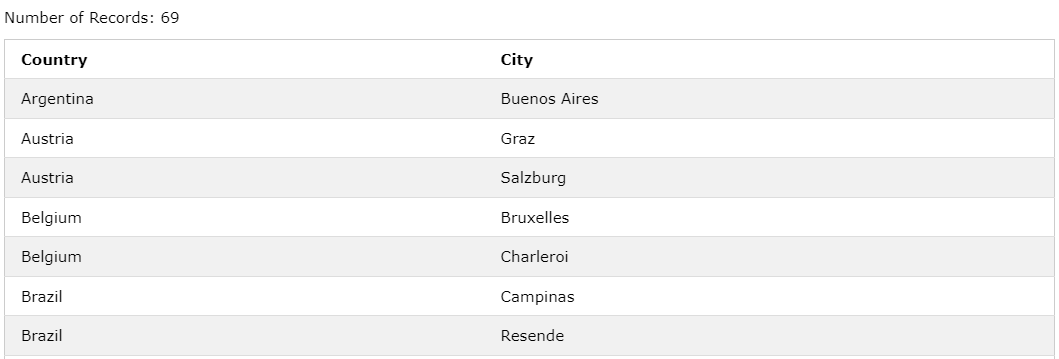
DISTINCT와 GROUP BY절
- DISTINCT는 주로 UNIQUE(중복을 제거)한 컬럼이나 레코드를 조회하는 경우 사용한다.
- GROUP BY는 데이터를 그룹핑해서 그 결과를 가져오는 경우 사용한다.
- 하지만 두 작업은 조금만 생각해보면 동일한 형태의 작업이라는 것을 쉽게 알 수 있으며,
일부 작업의 경우 DISTINCT로 동시에 GROUP BY로도 처리될 수 있는 쿼리들이 있다. - 두 기능 모두 Oracle9i까지는 sort를 이용하여 데이터를 만들었지만,
Oracle10g 부터는 모두 Hash를 이용하여 처리한다. - 그래서 DISTINCT를 사용해야 할지, GROUP BY를 사용해서 데이터를 조회하는 것이 좋을지 고민되는 경우들이 가끔 있다.
- 집계함수를 사용하여 특정 그룹으로 구분 할 때는GROUP BY 절을 사용하며,
특정 그룹 구분없이 중복된 데이터를 제거할 경우에는 DISTINCT 절을 사용 하도록 하자
💊 아래의 예제는 동일한 결과를 반환
-- DISTINCT를 사용한 중복 데이터 제거
SELECT DISTINCT deptno FROM emp;-- GROUP BY를 사용한 중복 데이터 제거
SELECT deptno FROM emp GROUP BY deptno;DEPTNO
------
30
20
10
💊 집계함수를 사용하여 특정 그룹으로 구분 할 때는GROUP BY 절을 사용하며,
특정 그룹 구분없이 중복된 데이터를 제거할 경우에는 DISTINCT 절을 사용
-- 아래와 같은 기능은 DISTINCT를 사용하는 것이 훨씬 효율적이다.
SELECT COUNT(DISTINCT d.deptno) "중복제거 수",
COUNT(d.deptno) "전체 수"
FROM emp e, dept d
WHERE e.deptno = d.deptno;
-- 집계 함수가 필요한 경우는 GROUP BY를 사용해야 한다.
SELECT deptno, MIN(sal)
FROM emp
GROUP BY deptno;
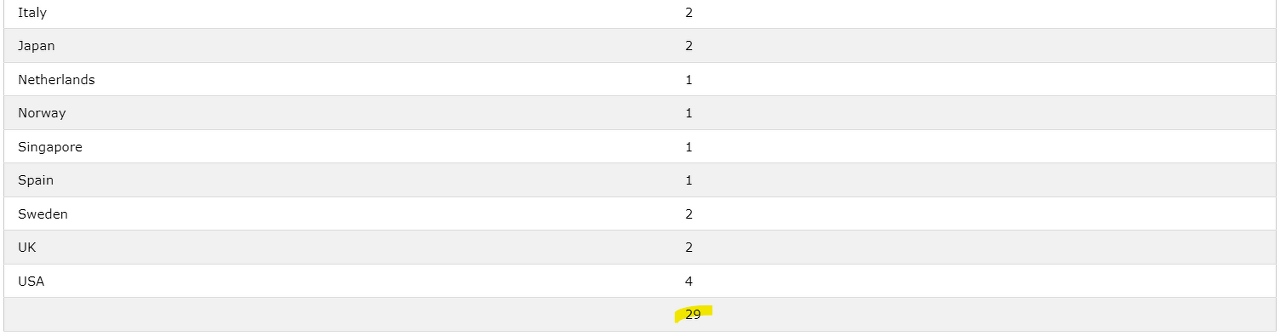
✔️ GROUP BY와 DISTINCT 같이 사용
SELECT
Country,
COUNT(DISTINCT CITY)
FROM Customers
GROUP BY Country;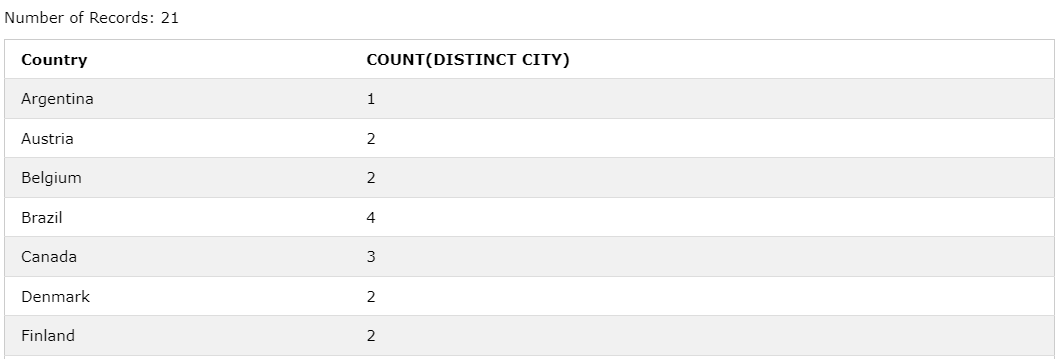
HAVING 절
- WHERE 절에서는 집계함수를 사용 할 수 없다.
- HAVING 절은 집계함수를 가지고 조건비교를 할 때 사용한다.
- HAVING절은 GROUP BY절과 함께 사용이 된다.
💊 사원수가 다섯 명이 넘는 부서와 사원수를 조회하는 예제
SELECT b.dname, COUNT(a.empno) "사원수"
FROM emp a, dept b
WHERE a.deptno = b.deptno
GROUP BY dname
HAVING COUNT(a.empno) > 5;
DNAME 사원수
------------ -------
SALES 6
💊 전체 월급이 5000을 초과하는 JOB에 대해서 JOB과 월급여 합계를 조회하는 예제
( 단 판매원(SALES)은 제외하고 월 급여 합계로 내림차순 정렬하였다. )
SELECT job, SUM(sal) "급여합계"
FROM emp
WHERE job != 'SALES' -- 판매원은 제외
GROUP BY job -- 업무별로 Group By
HAVING SUM(sal) > 5000 -- 전체 월급이 5000을 초과하는
ORDER BY SUM(sal) DESC; -- 월급여 합계로 내림차순 정렬
JOB 급여합계
------------------ ----------
MANAGER 8275
ANALYST 6000
SALESMAN 5600SELECT
Country, COUNT(*) AS Count
FROM Suppliers
GROUP BY Country
HAVING Count >= 3;
SELECT
COUNT(*) AS Count, OrderDate
FROM Orders
WHERE OrderDate > DATE('1996-12-31')
GROUP BY OrderDate
HAVING Count > 2;
SELECT
CategoryID,
MAX(Price) AS MaxPrice,
MIN(Price) AS MinPrice,
TRUNCATE((MAX(Price) + MIN(Price)) / 2, 2) AS MedianPrice,
TRUNCATE(AVG(Price), 2) AS AveragePrice
FROM Products
WHERE CategoryID > 2
GROUP BY CategoryID
HAVING
AveragePrice BETWEEN 20 AND 30
AND MedianPrice < 40;
WITH ROLLUP
전체 집계 값
집계함수 쿼리 끝에 출력 됨
⚠️ ORDER BY와 함계 사용 못 함
SELECT
Country, COUNT(*)
FROM Suppliers
GROUP BY Country
WITH ROLLUP;